探究 Java HashMap get 操作的时间复杂度
0x00 前言
最近刷 leetcode,又回去回顾了很多数据结构的知识。刷题时经常会碰到使用 HashMap 来实现 O(1) 时间内的元素快速查找,以空间换时间。Hash 表的基本原理就是对 key 进行哈希运算得出 HasCode,然后通过对 HashCode 进行变换得到数组的 index。最后将 value 插入到该 index 位置上。但实际上,并不存在完美的散列算法能使得对于每个不同的输入值都能得到独一无二的 HashCode。这也就意味着对于不同的输入值可能会产生相同的 index,这也就是哈希碰撞。对于哈希碰撞大体上有两种解决方案:按照一定规则寻找数组中其他空余的位置,将 value 插入该位置;在 index 位置上使用链表来保存相同 HashCode 的 key 对应的 value。Java 选择了后者的实现方式。那么问题就来了,在对 HashMap 进行 get 操作的时候,势必要进行 key 值的比较。如果 Key 的长度很大的话,HashMap 的 get 操作耗时应该会显著增加,那么是不是这样呢? 今天研究了一下这个问题。
0x01 Java 的 HashMap 是如何 get 到目标值的
如上面所说的,为了解决哈希碰撞问题,在对 HashMap 进行 put 操作的时候,有几率会在同一个 index 的位置上挂载多个 value,那么 get 操作想要获得正确的值就必须可以将查询时输入的 key 和 put 时保存在 HashMap 中的 key 值进行比较,相同时才返回 value,否则就继续向后遍历链表。流程如下面流程图所示:
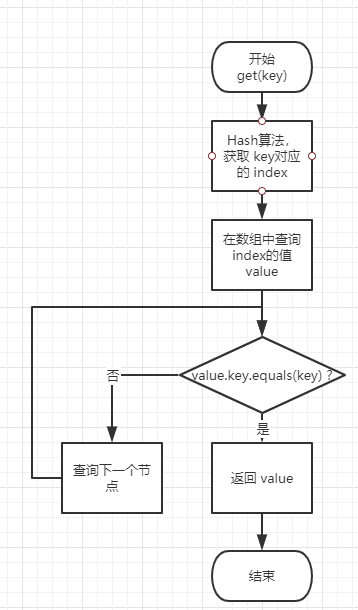
0x02 耗时点分析
由上面的流程可以知道, get 操作涉及了一步 value.key.equals(key) 的比较操作,如果 key 是 String 类型的话,那我们看下 String 是如何实现 equals 方法的:
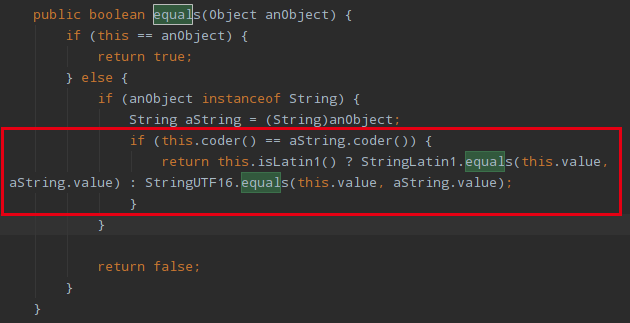
可以看到,在判断是否相同的时候会先比较字符串的 coder 是否相同,从coder方法中可以得知这个标志位是用来区分字符串是否是 Compact String 的,如果两个字符串的 coder 标志位不同也就说明两个字符串的类型有区别,那么就一定不同。如果相同,我们看到又继续执行了 StringLatin 或者 StringUTF16 的 equals 方法。这两个方法的实现很类似,我们以 StringLatin.equals 的实现为例来看:
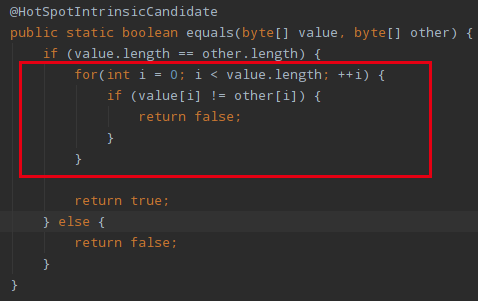
看到这里是使用了一个 for 循环来遍历两个字符串,逐字符比较两个字符串是否相同,那么这里的时间复杂度是 O(n)。
0x03 验证
通过以上的分析可知,HashMap.get 的真正时间复杂度其实是和 key 的判等速度有关的,并不是严格意义上的 O(1)。可见,在字符串作为 Key 的例子下如果使用很长字符串作为 Key,那么 HashMap.get 会耗费大量的时间来进行字符串的判等。下面做一个实验来检验一下这个结论:
1 | public class Solotion { |
运行得到以下输出:
1 | Connected to the target VM, address: '127.0.0.1:51865', transport: 'socket' |
可以看到产生了三个数量级的差距,这个差距还会随着 key 增长和元素增多而拉大。
结论
Key 的长度会影响到 HashMap.get 的效率,过多判等比较耗时的 Key 会导致 HashMap.get 变得很慢,所以尽量使用判等效率高的 Object 作为 Key 以获得最大的效率。